3.3 通用的并发模板 #
示例:并行循环 #
- 探讨一些通用的并行模式,来并行执行所有的循环迭代;
- 示例:生成一批全尺寸图片的缩略图的问题。很明显,处理文件的顺序没有关系,因为每一个缩放操作和其他的操作独立,通过并行可以利用多核CPU的计算能力拉伸图像,隐藏文件IO产生的延迟。像这样由一些完全独立的子问题组成的问题称为高度并行。高度并行的问题是最容易实现并行的,有许多并行机制来实现线性扩展。
- 简单的加go关键字,但产生了一个bug:
1 2 3 4 5func makeThumbnails2(filenames []string) { for _, f := range filenames { go thumbnail.ImageFile(f) // bug:启动了所有的goroutine,每一个文件名对应一个,**但没有等待它们一直到执行完毕而立即返回了**。 } } - 匿名函数中的循环变量快照问题: 下面这个单独的变量f是被所有的匿名函数值所共享,且会被连续的循环迭代所更新的。当新的goroutine开始执行字面函数时,for循环可能已经更新了f并且开始了另一轮的迭代或者(更有可能的)已经结束了整个循环,所以当这些goroutine开始读取f的值时,它们所看到的值已经是slice的最后一个元素了;
1 2 3 4 5 6 7// for _, f := range filenames { go func() { thumbnail.ImageFile(f) // NOTE: incorrect! // ... }() } - 注意,这里作为一个字面量函数的显式参数传递f,而不是使用在for循环中声明的f:可以确保当go语句执行的时候,使用f的当前循环的值
1 2 3 4 5 6 7 8 9 10 11 12 13func makeThumbnails3(filenames []string) { ch := make(chan struct{}) for _, f := range filenames { go func(f string) { // 两条语句封装成一个匿名函数 thumbnail.ImageFile(f) ch <- struct{}{} // 向一个共享的channel中发送事件(“事件”在channel中有介绍) }(f) // 注意我们将f的值作为一个显式的变量传给了函数,而不是在循环的闭包中声明; } // Wait for goroutines to complete. for range filenames { <-ch } } - 每一个
worker goroutine中向main goroutine返回,这里产生了goroutine泄漏:当遇到第一个非nil的错误时,它将错误返回给调用者,这样没有goroutine继续从errors返回通道上进行接收,直至读完。每一个现存的工作goroutine在试图发送值到此通道的时候永久阻塞,永不终止。这种情况下goroutine泄漏可能导致整个程序卡住或者系统内存耗尽(out of memory,oom);1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17// makeThumbnails4 makes thumbnails for the specified files in parallel. // It returns an error if any step failed. func makeThumbnails4(filenames []string) error { errors := make(chan error) for _, f := range filenames { go func(f string) { _, err := thumbnail.ImageFile(f) errors <- err // 无缓存chan,goroutine一直在等待chan清空后写入 }(f) } for range filenames { if err := <-errors; err != nil { return err // NOTE: incorrect: goroutine leak! } } return nil } - 解法:
- 方案1:使用一个有足够容量的缓冲通道,这样没有worker goroutine在发送消息时候阻塞;
- 方案2:在主goroutine返回第一个错误的同时,创建另一个goroutine来接收完通道;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22func makeThumbnails5(filenames []string) (thumbfiles []string, err error) { type item struct { thumbfile string err error } ch := make(chan item, len(filenames)) // 文件总数长度的缓冲通道 for _, f := range filenames { go func(f string) { var it item it.thumbfile, it.err = thumbnail.ImageFile(f) ch <- it }(f) } for range filenames { it := <-ch if it.err != nil { return nil, it.err } thumbfiles = append(thumbfiles, it.thumbfile) } return thumbfiles, nil } - 使用一个缓冲通道来返回生成的图像文件的名称以及任何错误消息,返回新文件所占用的总字节数。
- 这个版本里没有把文件名放在slice里,而是通过一个string的channel传过来,所以我们无法对循环的次数进行预测。
- sync.WaitGroup /sɪŋk/****计数器类型: 为了知道什么时候最后一个goroutine结束(它不一定是最后启动的),需要在每一个goroutine启动前递增计数,在每一个goroutine结束时递减计数。这需要一个特殊类型的计数器,它可以被多个goroutine安全地操作,然后有一个方法一直等到它变为0。
- 注意Add和Done方法的不对称性。
- Add递增计数器,它必须在工作goroutine开始之前执行,而不是在中间。另一方面,不能保证Add会在关闭者goroutine调用Wait之前发生。
- Add有一个参数,但Done没有,它等价于Add(-1)。使用defer来确保在发送错误的情况下计数器可以递减。
- sizes通道将每一个文件的大小带回主goroutine,它使用range循环进行接收然后计算总和。注意,在closer goroutine中,在关闭sizes通道之前,等待所有的工作者结束。这里两个操作(等待和关闭)必须和在sizes通道上面的迭代并行执行。考虑替代方案:如果我们将等待操作放在循环之前的main goroutine中,因为通道会满,它将永不结束;如果放在循环后面,它将不可达,因为没有任何东西可用来关闭通道,循环可能永不结束;
- 在不知道迭代次数的情况下,该代码结构是通用的、符合习惯的、地道的并行循环模式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26func makeThumbnails6(filenames <-chan string) int64 { sizes := make(chan int64) var wg sync.WaitGroup // number of working goroutines for f := range filenames { wg.Add(1) // Add是为计数器加一,必须在**worker goroutine**开始之前调用,而不是在goroutine中 (否则的话我们没办法确定Add是在"closer" goroutine调用Wait之前被调用) go func(f string) { // worker defer wg.Done() // Done却没有任何参数;其实它和Add(-1)是等价的;使用defer来确保计数器即使是在出错的情况下依然能够正确地被减掉。 thumb, err := thumbnail.ImageFile(f) if err != nil { log.Println(err) return } info, _ := os.Stat(thumb) // OK to ignore error sizes <- info.Size() }(f) } go func() { // closer goroutine,让其在所有worker goroutine们结束之后再关闭sizes channel的 wg.Wait() close(sizes) }() var total int64 for size := range sizes { // sizes channel携带了每一个文件的大小到main goroutine,在main goroutine中使用了range loop来计算总和。 total += size } return total }
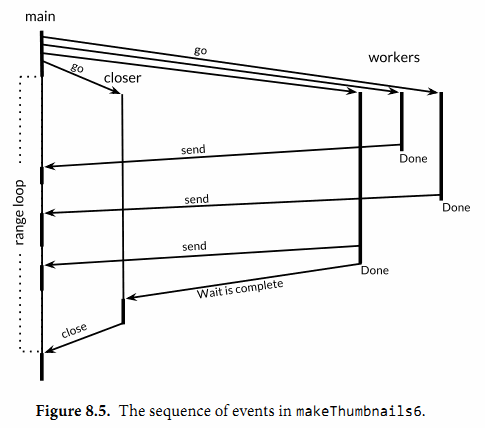
- 下图表明makeThumbnails6函数中的事件序列。
- 垂直线表示goroutine。细片段表示休眠,粗片段表示活动。
- 斜箭头表示goroutine通过事件进行了同步。时间从上向下流动。
- 注意,主goroutine把大多数时间花在range循环休眠上,等待工作者发送值或等待closer来关闭通道。
- 简单的加go关键字,但产生了一个bug:
示例: 并发的Web爬虫 #
- 匿名函数章节我们做了一个简单的web爬虫,用bfs(广度优先)算法来抓取整个网站;现在让这个爬虫并发运行,这样对crawl的独立调用可以充分利用Web上的I/O并行机制,最大化利用网络资源;
- 示例:crawl1.go
- 发送给任务列表的命令行参数必须在它自己的goroutine中运行来避免死锁,死锁是一种卡住的情况,其中主goroutine和一个爬取goroutine同时发送给对方但是双方都没有接收。另一个可选的方案是使用缓冲通道。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23func crawl(url string) []string { fmt.Println(url) list, err := links.Extract(url) if err != nil { log.Print(err) } return list } func main() worklist := make(chan []string) // 待抓取的URL列表,这里channel代替slice来做这个队列 go func() { worklist <- os.Args[1:] }() { // 另启一个goroutine,避免死锁(也可用缓冲通道)。 seen := make(map[string]bool) for list := range worklist { for _, link := range list { if !seen[link] { seen[link] = true go func(link string) { worklist <- crawl(link) }(link) // 显示传参,避免循环变量捕获 } } } } - bug:
- 程序的并行度太高了,无限制的并行通常不是一个好的主意,因为系统中总有限制因素(如:对于计算型应用CPU的核数,对于磁盘I/O操作磁头和磁盘的个数,下载流所使用的网络带宽,或者Web服务本身的容量);
- 解决方法:根**据资源可用情况限制并发的个数,以匹配合适的并行度:**如限制对于links.Extract的同时调用不超过n个;
1 2 3 4 5 6 7 8$ go build gopl.io/ch8/crawl1 $ ./crawl1 http://gopl.io/ http://gopl.io/ https://golang.org/help/ ... 2015/07/15 18:22:12 Get ...: dial tcp: lookup blog.golang.org: no such host // 对一个可靠的域名出现了解析失败 2015/07/15 18:22:12 Get ...: dial tcp 23.21.222.120:443: socket: too many open files // 同时创建了太多的网络连接,超过了程序能打开文件数的限制 ... - 计数信号量:使用容量为n的缓冲通道来建立一个并发原语。概念上,对于缓冲通道中的n个空闲槽,每一个代表一个令牌,持有者可以执行。
- 通过发送一个值到通道中来领取令牌,从通道中接收一个值来释放令牌,创建一个新的空闲槽。
- 这保证了在没有接收操作的时候,最多同时有n个发送。(尽管使用已填充槽比令牌更直观,但使用空闲槽在创建通道缓冲区之后可以省掉填充的过程)
- 因为通道的元素类型在这里不重要,所以我们使用struct{},它所占用的空间大小是0;
- 示例:重写crawl2.go,使用令牌的获取和释放操作来包括对links.Extract函数的调用,这样保证最多同时20个调用可以进行。保持信号量操作离它所约束的I/O操作越近越好——这是一个好的实践:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33var tokens = make(chan struct{}, 20) // **计数信号量 tokens,确保并发请求限制在20个以内** func crawl(url string) []string { fmt.Println(url) // 重写crawl函数,将对links.Extract的调用操作用获取、释放token的操作包裹起来,来确保同一时间对其只有20个调用。信号量数量和其能操作的IO资源数量应保持接近。 tokens <- struct{}{} // acquire a token list, err := links.Extract(url) <-tokens // release the token if err != nil { log.Print(err) } return list } func main() { worklist := make(chan []string) var n int // 计数器n跟踪发送到任务列表中的任务个数。每次知道一个条目被发送到任务列表时,就递增变量n; // Start with the command-line arguments. n++ // n的第一次递增是在发送初始化命令行参数之前 go func() { worklist <- os.Args[1:] }() // Crawl the web concurrently. seen := make(map[string]bool) for ; n > 0; n-- { // 主循环从n减到0,这时再没有任务需要完成 list := <-worklist for _, link := range list { if !seen[link] { // 为了让程序终止,当任务列表为空且爬取goroutine都结束以后,需要从主循环退出 seen[link] = true n++ // n的第二次及以后的递增 go func(link string) { worklist <- crawl(link) }(link) } } } }
- 发送给任务列表的命令行参数必须在它自己的goroutine中运行来避免死锁,死锁是一种卡住的情况,其中主goroutine和一个爬取goroutine同时发送给对方但是双方都没有接收。另一个可选的方案是使用缓冲通道。
- 另一个方案:使用原来的crawl函数,它没有计数信号量,但是通过20个长期存活/常驻的爬虫goroutine来调用它,这样确保最多20个HTTP请求并发执行;
- 爬取goroutine使用同一个通道unseenLinks进行接收。主goroutine负责对从任务列表接收到的条目进行去重,然后发送每一个没有爬取过的条目到unseenLinks通道,然后被爬取goroutine接收。
- seen map被限制在主goroutine里面,它仅仅需要被这个goroutine访问。与其他形式的信息隐藏一样,范围限制可以帮助我们推导程序的正确性。如,局部变量不能在声明它的函数之外通过名字引用;没有从函数中逃逸的变量不能从函数外面访问;一个对象的封装域只能被对象自己的方法访问。所有的场景中,信息隐藏帮助限制程序不同部分之间不经意的交互。
- crawl发现的链接通过精心设计的goroutine发送到任务列表来避免死锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29// 所有的爬虫goroutine现在都是被同一个channel - unseenLinks喂饱的了。主goroutine负责拆分它从worklist里拿到的元素,然后把没有抓过的经由unseenLinks channel发送给一个爬虫的goroutine。 // seen这个map被限定在main goroutine中;也就是说这个map只能在main goroutine中进行访问。类似于其它的信息隐藏方式,这样的约束可以让我们从一定程度上保证程序的正确性。例如,内部变量不能够在函数外部被访问到;变量(§2.3.4)在没有发生变量逃逸(译注:局部变量被全局变量引用地址导致变量被分配在堆上)的情况下是无法在函数外部访问的;一个对象的封装字段无法被该对象的方法以外的方法访问到。在所有的情况下,信息隐藏都可以帮助我们约束我们的程序,使其不发生意料之外的情况。 // crawl函数爬到的链接在一个专有的goroutine中被发送到worklist中来避免死锁。 func main() { worklist := make(chan []string) // lists of URLs, may have duplicates unseenLinks := make(chan string) // de-duplicated URLs // Add command-line arguments to worklist. go func() { worklist <- os.Args[1:] }() // Create 20 crawler goroutines to fetch each unseen link. for i := 0; i < 20; i++ { go func() { for link := range unseenLinks { foundLinks := crawl(link) go func() { worklist <- foundLinks }() } }() } // The main goroutine de-duplicates worklist items // and sends the unseen ones to the crawlers. seen := make(map[string]bool) for list := range worklist { for _, link := range list { if !seen[link] { seen[link] = true unseenLinks <- link } } } }
示例:使用select case多路复用
#
- 示例:火箭发射的倒计时 countdown1.go
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15func main() { fmt.Println("Commencing countdown.") // ime.Tick函数返回一个 <-chan Time 类型,程序会周期性地像一个节拍器一样向这个channel发送事件 tick := time.Tick(1 * time.Second) for countdown := 10; countdown > 0; countdown-- { fmt.Println(countdown) <-tick } launch() } abort := make(chan struct{}) go func() { // // 启动一个goroutine,这个goroutine会尝试从标准输入中读入一个单独的byte并且,如果成功了,会向名为abort的channel发送一个值。 os.Stdin.Read(make([]byte, 1)) // read a single byte abort <- struct{}{} }()- select语句的通用形式: 像switch语句一样,它有一系列的case和一个可选的和最后的default分支。
- 每一个情况指定一次通信(在一些通道上进行发送或接收操作)和关联的一段代码块。
- 接收表达式操作可能出现在它本身上,像第一个情况,或者在一个短变量声明中,像第二个情况;第二种形式可以让你引用所接收的值。
- select一直等待,直到一次通信来告知有一些情况可以执行。然后,它进行这次通信,执行此情况所对应的语句;其他的通信将不会发生。对于没有对应情况的select, select{}将永远等待。
- 如果多个case同时满足,select随机选择一个,这样保证每一个通道有相同的机会被选中。在前一个例子中增加缓冲区的容量,会使输出变得不可确定,因为当缓冲既不空也不满的情况,相当于select语句在扔硬币做选择。
1 2 3 4 5 6 7 8 9 10select { case <-ch1: // ... case x := <-ch2: // ...use x... case ch3 <- y: // ... default: // ... }1 2 3 4 5 6 7 8 9 10 11 12 13// 下面的select语句会一直等待直到两个事件中的一个到达,无论是abort事件或者一个10秒经过的事件。如果10秒经过了还没有abort事件进入,那么火箭就会发射 func main() { // ...create abort channel... fmt.Println("Commencing countdown. Press return to abort.") select { case <-time.After(10 * time.Second): // Do nothing. case <-abort: fmt.Println("Launch aborted!") return } launch() }
- select语句的通用形式: 像switch语句一样,它有一系列的case和一个可选的和最后的default分支。
- 下面这个例子更微妙:ch这个channel的buffer大小是1,所以会交替的为空或为满,所以只有一个case可以进行下去,无论i是奇数或者偶数,它都会打印0 2 4 6 8。
1 2 3 4 5 6 7 8ch := make(chan int, 1) for i := 0; i < 10; i++ { select { case x := <-ch: // ch为空时,跳过这个case;ch有值时,执行这个case; fmt.Println(x) // "0" "2" "4" "6" "8" case ch <- i: } } - 示例:让发射程序打印倒计时。select语句使每一次迭代使用1s来等待中止;gopl.io/ch8/countdown3
- time.Tick函数的行为很像创建一个goroutine在循环里面调用time.Sleep,然后在它每次醒来时发送事件。当上面的倒计时函数返回时,它停止从tick通道中接收事件,但是计时器goroutine还在运行,徒劳地向一个没有goroutine在接收的通道不断发送(发生goroutine泄漏);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16func main() { // ...create abort channel... fmt.Println("Commencing countdown. Press return to abort.") tick := time.Tick(1 * time.Second) for countdown := 10; countdown > 0; countdown-- { fmt.Println(countdown) select { case <-tick: // Do nothing. case <-abort: fmt.Println("Launch aborted!") return } } launch() }- Tick函数很方便使用,但是它仅仅在应用的整个生命周期中都需要时才合适。否则,我们需要使用这个模式:
1 2 3ticker := time.NewTicker(1 * time.Second) <-ticker.C // receive from the ticker's channel ticker.Stop() // cause the ticker's goroutine to terminate
- 有时候我们试图在一个通道上发送或接收,但不想在通道没有准备好的情况下被阻塞(非阻塞通信)。这使用select语句也可以做到。select可以有一个默认情况,它用来指定在没有其他的通信发生时可以立即执行的动作。
- 面的select语句从尝试从abort通道中接收一个值,如果没有值,它什么也不做。这是一个非阻塞的接收操作;重复这个动作称为对通道轮询:
1 2 3 4 5 6 7select { case <-abort: fmt.Printf("Launch aborted!\n") return default: // do nothing } - 通道的零值是nil。令人惊讶的是,nil通道有时候很有用。因为在nil通道上发送和接收将永远阻塞,对于select语句中的情况,如果其通道是nil,它将永远不会被选择。这次让我们用nil来开启或禁用特性所对应的情况,比如超时处理或者取消操作,响应其他的输入事件或者发送事件。
示例: 并发的目录遍历 #
- 示例:报告一个或多个目录的磁盘使用情况(类似于UNIX du命令)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21// walkDir recursively walks the file tree rooted at dir // and sends the size of each found file on fileSizes. func walkDir(dir string, fileSizes chan<- int64) { for _, entry := range dirents(dir) { if entry.IsDir() { subdir := filepath.Join(dir, entry.Name()) walkDir(subdir, fileSizes). // 每个子目录递归调用自身 } else { fileSizes <- entry.Size() // 向fileSizes channel发送一条消息,内容为文件的字节大小的 } } } // dirents returns the entries of directory dir. func dirents(dir string) []os.FileInfo { entries, err := ioutil.ReadDir(dir). // 返回一个os.FileInfo类型的slice,os.FileInfo类型也是os.Stat这个函数的返回值 if err != nil { fmt.Fprintf(os.Stderr, "du1: %v\n", err) return nil } return entries }- main函数
- 后台的goroutine调用walkDir来遍历命令行给出的每一个路径并最终关闭fileSizes这个channel。
- 主goroutine会对其从channel中接收到的文件大小进行累加,并输出其和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34package main import ( "flag" "fmt" "io/ioutil" "os" "path/filepath" ) func main() { // Determine the initial directories. flag.Parse() roots := flag.Args() if len(roots) == 0 { roots = []string{"."} } // Traverse the file tree. fileSizes := make(chan int64) go func() { // 后台goroutine for _, root := range roots { walkDir(root, fileSizes) } close(fileSizes) }() // Print the results. var nfiles, nbytes int64 for size := range fileSizes { nfiles++ // 直接++,Go的零值初始化的机制带来的更简洁的代码 nbytes += size } printDiskUsage(nfiles, nbytes) } func printDiskUsage(nfiles, nbytes int64) { fmt.Printf("%d files %.1f GB\n", nfiles, float64(nbytes)/1e9) } - 思考:这个程序会在打印其结果之前运行很长时间,如果在运行的时候能够让我们知道处理进度的话想必更好。但如果简单地把printDiskUsage函数调用移动到循环里会导致其打印出成百上千的输出;
- 下面这个du的变种会间歇打印内容,不过只有在调用时提供了-v的flag才会显示程序进度信息
- 主goroutine现在使用了计时器来每500ms生成事件,然后用select语句来等待文件大小的消息来更新总大小数据,或者一个计时器的事件来打印当前的总大小数据;
- 如果-v的flag在运行时没有传入的话,tick这个channel会保持为nil,这样在select里的case也就相当于被禁用了
- 由于我们的程序不再使用range循环,第一个select的case必须显式地判断fileSizes的channel是不是已经被关闭了,这里可以用到channel接收的二值形式。如果channel已经被关闭了的话,程序会直接退出循环。
- 这里的break语句用到了标签break,这样可以同时终结select和for两层循环;如果没有用标签就break的话只会退出内层的select循环,而外层的for循环会使之进入下一轮select循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25var verbose = flag.Bool("v", false, "show verbose progress messages") func main() { // ...start background goroutine... // Print the results periodically. var tick <-chan time.Time if *verbose { tick = time.Tick(500 * time.Millisecond) } var nfiles, nbytes int64 loop: for { select { case size, ok := <-fileSizes: if !ok { break loop // fileSizes was closed**。标签break,这样可以同时终结select和for两层循环** } nfiles++ nbytes += size case <-tick: printDiskUsage(nfiles, nbytes) } } printDiskUsage(nfiles, nbytes) // final totals } - 思考:并发调用walkDir,从而发挥磁盘系统的并行性能:对每一个walkDir的调用创建一个新的goroutine。
- 它使用sync.WaitGroup来对仍旧活跃的walkDir调用进行计数,另一个goroutine会在计数器减为零的时候将fileSizes这个channel关闭;
- 由于这个程序在高峰期会创建成百上千的goroutine,我们需要修改dirents函数,用计数信号量来阻止他同时打开太多的文件,就像前面的并发爬虫一样;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34func main() { // ...determine roots... // Traverse each root of the file tree in parallel. fileSizes := make(chan int64) var n sync.WaitGroup for _, root := range roots { n.Add(1) go walkDir(root, &n, fileSizes) } go func() { n.Wait() close(fileSizes) }() // ...select loop... } func walkDir(dir string, n *sync.WaitGroup, fileSizes chan<- int64) { defer n.Done() for _, entry := range dirents(dir) { if entry.IsDir() { n.Add(1) subdir := filepath.Join(dir, entry.Name()) go walkDir(subdir, n, fileSizes) } else { fileSizes <- entry.Size() } } } // sema is a counting semaphore for limiting concurrency in dirents. var sema = make(chan struct{}, 20) // dirents returns the entries of directory dir. func dirents(dir string) []os.FileInfo { sema <- struct{}{} // acquire token defer func() { <-sema }() // release token // ...
- main函数
示例:并发的退出 #
- 有时候我们需要通知goroutine停止它当前的任务;如:一个Web服务器对客户请求处理到一半的时候客户端断开了;
- 一个goroutine无法直接终止另一个,因为这样会让所有goroutine之间的共享变量状态处于不确定状态。在8.7节的火箭发射程序中,我们给abort通道发送一个值,倒计时goroutine把它理解为停止自己的请求。但是怎样才能取消两个或者指定个数的goroutine呢?
- 一个可能是给abort通道发送和要取消的goroutine同样多的事件。如果一些goroutine已经自己终止了,这样计数就多了,然后发送过程会卡住。如果那些goroutine可以自我繁殖,数量又会太少,其中一些goroutine依然不知道要取消。
- 通常,任何时刻都很难知道有多少goroutine正在工作。更多情况下,当一个goroutine从abort通道接收到值时,它利用这个值,这样其他的goroutine接收不到这个值。对于取消操作,我们需要一个可靠的机制通过一个通道广播一个事件,这样goroutine们能够看到这条事件消息,并且在事件完成之后,可以知道这件事已经发生过
- **回忆一下,当一个通道关闭 且已取完所有发送的值 之后,接下来的接收操作立即返回,得到零值。**我们可以利用它创建一个广播机制:不在通道上发送值,而是用关闭一个通道来进行广播
- dup的修改版本 gopl.io/ch8/du4:
- 第一步,创建一个取消通道,在它上面不发送任何值,但是它的关闭表明程序需要停止它正在做的事情。也定义了一个工具函数cancelled,在它被调用的时候检测或轮询取消状态;
1 2 3 4 5 6 7 8 9var done = make(chan struct{}) func cancelled() bool { // 工具函数 select { case <-done: return true default: return false } } - 第二步:创建一个读取标准输入的goroutine,这是一个比较典型的连接到终端的程序。一旦开始读取任何输入(如用户按回车键)时,这个goroutine通过关闭done通道来广播取消事件
1 2 3 4 5// Cancel traversal when input is detected. go func() { os.Stdin.Read(make([]byte, 1)) // read a single byte close(done) }() - 第三步:让goroutine来响应取消操作。在主goroutine中,添加第三个情况到select语句中,它尝试从done通道接收。如果选择这个情况,函数将返回,但是在返回之前它必须耗尽fileSizes通道,丢弃它所有的值,直到通道关闭。做这些是为了保证所有的walkDir调用可以执行完,不会卡在向fileSizes通道发送消息上。
1 2 3 4 5 6 7 8 9 10 11 12for { select { case <-done: // Drain fileSizes to allow existing goroutines to finish. for range fileSizes { // Do nothing. } return case size, ok := <-fileSizes: // ... } } - walkDir goroutine在开始的时候轮询取消状态,如果设置状态,什么都不做立即返回。它让在取消后创建的goroutine什么都不做:
- 在walkDir循环中来进行取消状态轮询也许是划算的,它避免在取消后创建新的goroutine。取消需要权衡:更快的响应通常需要更多的程序逻辑变更入侵。确保在取消事件以后没有更多昂贵的操作发生,可能需要更新代码中很多的地方,但通常我们可以通过在少量重要的地方检查取消状态来达到目的。
1 2 3 4 5 6 7 8 9func walkDir(dir string, n *sync.WaitGroup, fileSizes chan<- int64) { defer n.Done() if cancelled() { return } for _, entry := range dirents(dir) { // ... } } - 现在,当取消事件发生时,所有的后台goroutine迅速停止,然后main函数返回。当然,当main返回时,程序随之退出,不过这里没有谁在后面通知main函数来进行清理。在测试中有一个技巧:如果在取消事件到来的时候main函数没有返回,执行一个panic调用,然后运行时将转储程序中所有goroutine的栈。如果主goroutine是最后一个剩下的goroutine,它需要自己进行清理。但如果还有其他的goroutine存活,它们可能还没有合适地取消,或者它们已经取消,可是需要的时间比较长;多一点调查总是值得的。崩溃转储信息通常含有足够的信息来分辨这些情况。
- 第一步,创建一个取消通道,在它上面不发送任何值,但是它的关闭表明程序需要停止它正在做的事情。也定义了一个工具函数cancelled,在它被调用的时候检测或轮询取消状态;
- 程序的一点性能剖析揭示了它的瓶颈在于dirents中获取信号量令牌的操作。下面的select让取消操作的延迟从数百毫秒减为几十毫秒:
1 2 3 4 5 6 7 8 9func dirents(dir string) []os.FileInfo { select { case sema <- struct{}{}: // acquire token case <-done: return nil // cancelled } defer func() { <-sema }() // release token // ...read directory... }
示例: 并发的聊天服务器 #
- 示例: 并发的聊天服务器,可以在几个用户之间相互广播文本消息。这个程序里有4个goroutine。
- 主goroutine:监听端口,接受连接客户端的网络连接。对每一个连接,它创建一个新的handleConngoroutine,就像本章开始时并发回声服务器中那样。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15func main() { listener, err := net.Listen("tcp", "localhost:8000") if err != nil { log.Fatal(err) } go broadcaster() for { conn, err := listener.Accept() if err != nil { log.Print(err) continue } go handleConn(conn) } } - 广播器(broadcaster) goroutine:使用局部变量clients来记录当前连接的客户端集合。其记录的内容是每一个客户端的消息发出channel的“资格”信息
- 广播者监听两个全局的通道entering和leaving,通过它们通知客户的到来和离开,如果它从其中一个接收到事件,它将更新clients集合。
- 如果客户离开,那么它关闭对应客户对外发送消息的通道。广播者也监听来自messages通道的事件,所有的客户都将消息发送到这个通道。当广播者接收到其中一个事件时,它把消息广播给所有客户。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24type client chan<- string // an outgoing message channel var ( entering = make(chan client) leaving = make(chan client) messages = make(chan string) // all incoming client messages ) func broadcaster() { clients := make(map[client]bool) // all connected clients for { select { case msg := <-messages: // Broadcast incoming message to all // clients' outgoing message channels. for cli := range clients { cli <- msg } case cli := <-entering: clients[cli] = true case cli := <-leaving: delete(clients, cli) close(cli) } } } - handleConn函数创建一个对外发送消息的新通道,然后通过entering通道通知广播者新客户到来。接着,它读取客户发来的每一行文本,通过全局接收消息通道将每一行发送给广播者,发送时在每条消息前面加上发送者ID作为前缀。一旦从客户端读取完毕消息,handleConn通过leaving通道通知客户离开,然后关闭连接。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21func handleConn(conn net.Conn) { ch := make(chan string) // outgoing client messages go clientWriter(conn, ch) who := conn.RemoteAddr().String() ch <- "You are " + who messages <- who + " has arrived" entering <- ch input := bufio.NewScanner(conn) for input.Scan() { messages <- who + ": " + input.Text() } // NOTE: ignoring potential errors from input.Err() leaving <- ch messages <- who + " has left" conn.Close() } func clientWriter(conn net.Conn, ch <-chan string) { for msg := range ch { fmt.Fprintln(conn, msg) // NOTE: ignoring network errors } } - 另外,handleConn函数还为每一个客户创建了写入(clientWriter)goroutine,它接收消息,广播到客户的发送消息通道中,然后将它们写到客户的网络连接中。客户写入者的循环在广播者收到leaving通知并且关闭客户的发送消息通道后终止。
- 每一个连接里面有一个连接处理(handleConn)goroutine和一个客户写入(clientWriter)goroutine。广播器(broadcaster)是关于如何使用select的一个规范说明,因为它需要对三种不同的消息进行响应。
- 主goroutine:监听端口,接受连接客户端的网络连接。对每一个连接,它创建一个新的handleConngoroutine,就像本章开始时并发回声服务器中那样。
- 当有n个客户session在连接的时候,程序并发运行着2n+2个相互通信的goroutine,它不需要隐式的加锁操作(参考9.2节)。clients map限制在广播器这一个goroutine中被访问,所以不会并发访问它。唯一被多个goroutine共享的变量是通道以及net.Conn的实例,它们又都是并发安全的。关于限制、并发安全,以及跨goroutine的变量共享的含义,将在下一章进行更多的讨论。
