1.3 词法元素 #
注释 #
注释用作程序文档。有两种形式:
- 行注释以字符序列
//开头(C++风格),并在行尾结束。 - 块注释以字符序列
/*开头,并以第一个后续的字符序列*/结束(C风格)。 主要用作包的注释、禁用一大段代码。 不包含换行的普通注释类似于空格。其他任何注释类似于换行。
注释是不会被解析的纯文本**,不支持格式化(如用星号来突出等),**使用正确的拼写、标点和语句结构以及折叠长行等。
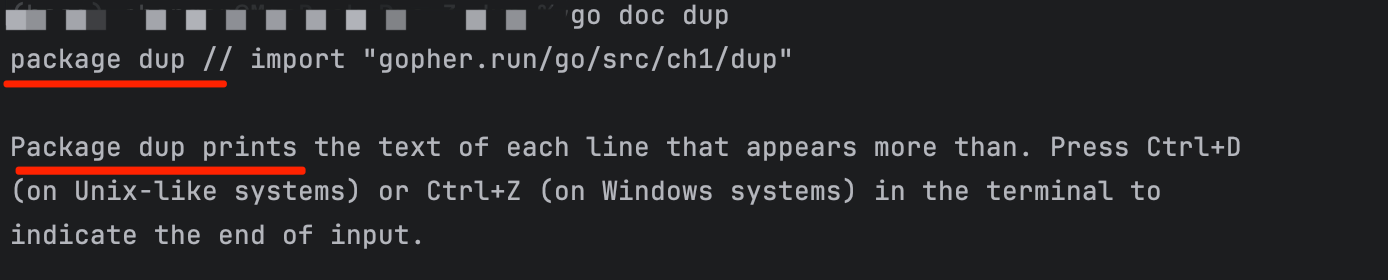
**包注释/文档注释:****每个可导出(首字母大写)的名称都应该有文档注释,**出现在顶级声明之前,且与该声明之间没有空行的注释。godoc程序将其与该声明一起被提取出来。包含多个文件的包,包注释只需出现在其中的任一文件中即可。。

| |
分号 #
Go的正式语法使用分号来结束语句,**但这些分号通常并不在源码中出现(除非一行上有多条语句,如For循环子句),词法分析器会在语句的行末自动插入分号。**行末标识的识别规则:
- 标识符(包括
**int**和**float64**这类的单词) - 数值
- 字符串常量之类的基本字面量
- 关键字:break、continue、fallthrough、return
- 运算符:++、–
- 闭括号: )、 ]、 }
格式化 #
格式化问题总是充满了争议,虽说人们可以适应不同的编码风格,但抛弃这种适应过程岂不更好?(第一性原理)。若所有人都遵循相同的编码风格,在这类问题上浪费的时间将会更少,也避免了无尽的无意义的琐碎争执(译注:也导致了Go语言的 TIOBE排名较低,因为缺少撕逼的话题);
在Go中我们另辟蹊径,让机器来处理大部分的格式化问题(而非使用冗长的语言风格规范);
gofmt 程序(也可用 go fmt,它以包为处理对象而非源文件)将Go程序按照标准风格缩进、对齐,保留注释并在需要时重新格式化;你无需花时间将结构体中的字段注释对齐,gofmt 将为你代劳。
缩进我们使用制表符(tab)缩进,gofmt 默认也使用它。在你认为确实有必要时再使用空格。
行的长度Go对行的长度没有限制,别担心打孔纸不够长。如果一行实在太长,也可进行折行并插入适当的tab缩进。
括号比起C和Java,Go所需的括号更少:控制结构(**if**、**for**** 和 **switch**)在语法上并不需要圆括号。**
此外,操作符优先级处理变得更加简洁,因此x<<8 + y<<16正表述了空格符所传达的含义
命名(标识符) #
命名规则:必须以一个字母(Unicode字母)或下划线开头,后面可以跟任意数量的字母、数字或下划线。如函数名、变量名、常量名、类型名、语句标号和包名等。
命名决定包外可见性的语义:如果一个名字是大写字母开头的(译注:必须是在函数外部定义的包级名字;包级函数名本身也是包级名字),那么它将是导出的。
驼峰命名法:**Go中约定使用驼峰记法 **MixedCaps** 或 **mixedCaps**(而Rust使用下划线命名)。而像ASCII和HTML这样的缩略词则****避免使用大小写混合的写法**,它们可能被称为htmlEscape(html纯小写)、HTMLEscape或escapeHTML(HTML纯大写),但不会是escapeHtml。
Lowercase production names are used to identify lexical (terminal) tokens.The underscore character _ (U+005F) is considered a lowercase letter.
小写生产名称用于标识词法(终结)符号。下划线字符 _ (U+005F) 被视为小写字母。
Non-terminals are in CamelCase. 非终结符使用驼峰命名法。
Lexical tokens are enclosed in double quotes "" or back quotes ``. 词法符号用双引号"“或反引号``` 括起来。
Identifiers 标识符 #
Identifiers name program entities such as variables and types. An identifier is a sequence of one or more letters and digits. The first character in an identifier must be a letter.
标识符命名程序实体,如变量和类型。标识符是由一个或多个字母和数字组成的序列。标识符的第一个字符必须是字母。
Some identifiers are predeclared.
某些标识符是预声明的。
空白标识符**_**
#
**作为匿名占位符代替非空标识符,用****在需要变量但不需要实际值的地方,可避免创建无用的变量,并能清楚地表明该值会被无害地丢弃,**可被赋予或声明为任何类型的任何值,只写。它有点像Unix中的 /dev/null 文件。
空标识符可以像其他任何标识符一样在声明中使用,但它不引入绑定,因此不被声明。
| |
将未使用的变量 fd 赋予空白标识符,也能关闭未使用变量错误:
| |
仅仅为了使用
net/http/pprof 包的 init 函数的记录了HTTP处理程序的调试信息,而不需要直接使用包时:
| |
若只需要判断某个类型是否是实现了某个接口,而不需要实际使用接口本身 (可能是错误检查部分),就使用空白标识符来忽略类型断言的值:
| |
确保某个包中实现的类型一定满足该接口:调用了一个 *RawMessage 转换并将其赋予了 Marshaler,以此来要求 *RawMessage 实现 Marshaler,这时其属性就会在编译时被检测。若json.Marshaler 接口被更改,此包将无法通过编译, 而我们则会注意到它需要更新。
不过请不要为满足接口就将它用于任何类型。作为约定,仅当代码中不存在静态类型转换时才能这种声明,毕竟这是种罕见的情况。
| |
简洁命名:
bufio.Reader:而非bufio.BufReader。**包名由于大量使用,**以小写的单个单词来命名,且不应使用下划线或驼峰记法。在src/pkg/encoding/base64中base64,而非encoding_base64或encodingBase64once.Do(setup):而非once.DoOrWaitUntilDone(setup)画蛇添足,一份有用的说明文档通常比额外的长名更有价值;ring.NewRing:用于创建ring.Ring的新实例的函数(构造函数),但此处由于Ring是该包所导出的唯一类型,且该包也叫ring,因此它可以只叫做ring.Newi:而非冗长的theLoopIndex,对于局部变量尤其用短小的名字。通常如果一个名字的作用域比较大,生命周期也比较长,那么用长的名字将会更有意义- Go需要自己写获取器(getter)和设置器(setter);若你有个名为
owner(小写,未导出)的字段,其获取器应当名为Owner(大写,可导出)而非GetOwner1 2 3 4owner := obj.Owner() if owner != user { obj.SetOwner(user) } - 字符串转换方法命名为
String,而非ToString。 - **只包含一个方法的接口应当以该方法的名称加上-er后缀来命名:**如
Reader、Writer、Formatter、CloseNotifier等,Read、Write、Close、Flush、String等都具有典型的签名和意义。为避免冲突,请不要用这些名称为你的方法命名, 除非你明确知道它们的签名和意义相同。
关键字与预定义的名字 #
关键字:关键字不能用于自定义名字,只能在特定语法结构中使用。Go语言中只有25个关键字;
| |
**内部预定义的名字:**37个,并不是关键字,可以在一些特殊的场景中重新定义,注意避免过度而引起语义混乱。
| |
为什么 Go 使用 nil 而不是 null?
- 历史原因: 来自 Lisp 语言的设计
- 语义准确: nil 表示"零值”,不仅仅是"空指针"
- 类型安全: nil 有类型信息,更安全
- 零值设计: 符合 Go 的零值设计理念
- 性能优势: 不需要内存分配
- 并发友好: nil 通道有特殊语义
- 接口支持: 支持 nil 接口的特殊处理
预定义类型 error 表示错误状态的常规接口,其中 nil 值表示没有错误。其被定义为
| |
运算符和标点符号 #
| |
字面量 #
整数字面量:由数字组成的序列,表示一个整数常量。
0b或0B表示二进制0、0o或0O表示八进制0x或0X表示十六进制 [Go 1.13],字母a到f和A到F分别表示 10 到 15 的值- 单个
0被视为十进制零 为了可读性,在基本前缀之后或连续数字之间可以出现下划线字符_;这样的下划线不会改变字面量的值。
| |
**浮点字面量:**表示一个浮点常数的十进制或十六进制
**虚数字面量:**表示复常数的一部分
**Rune字符字面量:**表示一个 rune 常量,即标识一个 Unicode 码点的整数值
String字符串字面量: 表示通过连接一系列字符得到的字符串常量。有两种形式:原始字符串字面量和解释字符串字面量。
| |