1.2 Hello, World #
一、hello world #
源码 #
以下是Go语言版本的hello world,“hello world”案例首次出现于1978年出版的C语言圣经《The C Programming Language》
| |
源码解读 #
- main package & main function:每个源文件都以一条
package声明语句开始,通过包(package)组织****(包类似于其它语言里的库(libraries)/模块(modules))。package main 定义了一个独立可执行的程序,而不是一个库。在main里的main函数也很特殊,它是整个程序执行时的入口(译注:C 系语言差不多都这样); - Unicode原生支持:Go的三位设计者中2位为UTF-8的设计者;
- import:紧跟着必须告诉编译器的一系列导入(import)的包。Go语言的代码:一个包由位于单个目录下的一个或多个
.go源代码文件组成,目录定义包的作用。Go严格要求:缺少了必要的包或者导入了不需要的包,程序都无法编译通过,避免了程序开发过程中引入未使用的包。goimports自动导入; - gofmt:Go语言在代码格式上**采取了很强硬的态度,**避免了无尽的无意义的琐碎争执(译注:也导致了Go语言的
TIOBE排名较低,因为缺少撕逼的话题)
- 编译器会主动把【特定符号清单】后的换行符转换为分号,包括:行末的标识符、整数、浮点数、虚数、字符或字符串文字、关键字
**break**、**continue**、**fallthrough**或**return**中的一个、运算符和分隔符**++**、**--**、**)**、**]**** 或**}**。** - 所以除非一行上有多条语句,否则不需要在语句或者声明的末尾添加分号(编辑器保存时会自动删除行末的分号,自动执行
gofmt自动格式化代码)。更重要的是,这样可以做多种自动源码转换,如果放任Go语言代码格式,这些转换就不大可能了。
- 编译器会主动把【特定符号清单】后的换行符转换为分号,包括:行末的标识符、整数、浮点数、虚数、字符或字符串文字、关键字
- Go标准库:提供了184个包,以支持常见功能,如输入、输出、排序以及文本处理;

go build & go run #
**go build helloworld.go**:编译;由于每个go程序都通过goroutine运行,go的二进制文件体积很大;体积对比:C版本 33k,go版本 2.1M(65倍);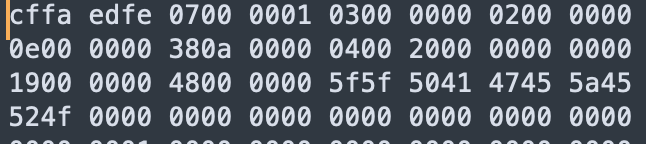
- C版本 hello,world: gcc -o hello hello.c
- C版本 hello,world: gcc -o hello hello.c
**go run helloworld.go**:编译后运行;
二、echo #
源码 #
大多数的程序都是:处理输入、产生输出;输入包括文件、网络连接、其它程序的输出、敲键盘的用户、命令行参数或其它类似输入源
| |
源码解读 #
- 包注释/文档注释:**按照惯例在每个包的包声明前,**以程序名开头,从整体角度对程序做个简要描述。
os包以与平台无关的方式提供了一些与操作系统交互的函数和变量。os.Args变量是一个字符串(string)的切片(slice)(/slaɪs/,动态数组)。和大多数编程语言类似,区间索引时,Go 语言里也采用左闭右开,因为这样可以简化逻辑。s[m:n],省略m和n时,会默认传入0或len(s)。- 导入多个包,习惯上用括号把它们括起来写成列表形式;
gofmt工具格式化时按照字母顺序对包名排序。 var声明:如果变量没有显式初始化,则被隐式地赋予其类型的零值(zero value),**数值类型是**0**,字符串类型是空字符串 ****""**- 符号
:=是**短变量声明(short variable declaration)**的一部分,这是定义一个或多个变量并根据它们的初始值为这些变量赋予适当类型的语句。只能用于在函数体中,而不能用在包级别; - 对数值类型,Go语言提供了常规的数值和逻辑运算符。而对
string类型,+运算符连接字符串(译注:和 C++ 或者 JavaScript 是一样的)。等价于:s=s+sep+os.Args[i]。 - 自增语句
i++:给i加1;这和i+=1以及i=i+1都是等价的。**表达式是赋值=的右边部分,而语句是独立完整一条。Go有意将**i++**设计成语句而不是表达式,简化了语言规范,提高了代码可读性,符合 Go 的"简单明确"设计哲学。Go中**j=i++**非法,**而且++和--都只能放在变量名后面,因此**--i**也非法。 s += sep + arg:- 创建了一个新的字符串,包含 s + sep + os.Args[i]
1 2 3 4 5// 假设循环执行过程 s = "" // 空字符串 s = "" + " " + "arg1" // 新字符串 " arg1",旧字符串 "" 可回收 s = " arg1" + " " + "arg2" // 新字符串 " arg1 arg2",旧字符串 " arg1" 可回收 s = " arg1 arg2" + " " + "arg3" // 新字符串 " arg1 arg2 arg3",旧字符串 " arg1 arg2" 可回收 - 将新字符串赋值给变量 s
- 旧的字符串内容变成了"垃圾",等待gc垃圾回收。如果连接涉及的数据量很大,这种方式代价高昂(注释:会产生大量的垃圾,进而产生大量的gc);Go 使用**并发标记清除(Concurrent Mark and Sweep)**垃圾回收器:
- 自动检测:GC 会自动检测不再被引用的内存
- 并发执行:GC 与程序并发运行,减少停顿时间
- 适时回收:在合适的时机回收垃圾内存
- 创建了一个新的字符串,包含 s + sep + os.Args[i]
- Go语言只有
**for**循环这一种循环语句。for循环有多种形式;**for**** 循环三个部分不需括号包围**。由于++为【特定符号清单】,结尾会自动加分号而导致编译错误,所以左大括号必须和***post***语句在同一行。1 2 3for initialization; condition; post { // zero or more statements }- for循环的这三个部分每个都可以省略,如果省略
initialization和post,分号也可以省略:1 2 3 4// a traditional "while" loop for condition { // ... } - 如果连
condition也省略了,像下面这样:这就变成一个无限循环,尽管如此,还可以用其他方式终止循环,如一条break或return语句。1 2 3 4// a traditional infinite loop for { // ... } forrange:在字符串或切片等数据类型的区间(range)上遍历1 2 3 4 5 6 7 8 9 10 11 12 13 14// echo prints its command-line arguments. package main import ( "fmt" "os" ) func main() { s, sep := "", "" for _, arg := range os.Args[1:] { s += sep + arg sep = " " } fmt.Println(s) }- 每次循环迭代,
range产生一对值;索引(数组下标)、在该索引处的元素值。 - 这个例子不需要索引,但
**range**** 的语法要求,要处理元素,必须处理索引**。一种思路是把索引赋值给一个临时变量(如temp)然后忽略它的值,但 Go 语言不允许使用无用的局部变量(local variables),因为这会导致编译错误。(注释:这种强制要求节省了不必要的局部变量内存空间) - 空标识符(blank identifier,即
_):在任何语法需要变量名但程序逻辑不需要的时候(如:在循环里),用于丢弃不需要的循环索引,并保留元素值。大多数的 Go 程序员都会像上面这样使用range和_写echo程序,因为隐式地而非显式地索引os.Args,容易写对。
- 每次循环迭代,
- for循环的这三个部分每个都可以省略,如果省略
- 使用显示的初始化来说明初始化变量的重要性;使用隐式的初始化来表明初始化变量不重要;
1 2 3 4s := "" // v1: 短变量声明,不能用于包级别变量,只能用在函数内部 var s string // v2:**依赖于字符串的默认初始化零值机制****,被初始化为 ""**。~~ var s = ""~~ // v3: 当声明多个变量时用到~~ var s string = ""~~ // v4:当变量类型与初值类型不同时使用
性能优化 #
源码:一种简单且高效的实现是:使用 strings 包的 Join 函数
| |
- 上述的函数注释会出现在IDE中的提示框

- 上述三个版本因为循环变量s的gc耗时,循环1亿次的性能对比相差高达一倍:

源码解读:看看标准库的实现
strings.Join源码:
| |
strings.Builder:
| |
内存使用对比:
| |
Go中将字符串设计为不可变的,优先保证安全性,再通过strings.Builder构建器优化性能。这意味着一切对字符串的操作都转换为:重新赋值,创建新字符串。
| |
| 语言 | 字符串特性 | 主要优势 | 性能优化方案 |
|---|---|---|---|
| C++ | 可变 | 性能高、内存效率 | 直接操作 |
| Rust | 可变 | 内存安全、性能高 | 直接操作 |
| Go | 不可变 | 线程安全、内存共享 | strings.Builder |
| Java | 不可变 | 线程安全、缓存友好 | StringBuilder |
| Python | 不可变 | 简单、安全 | join() 方法 |
| JavaScript | 不可变 | 简单、安全 | 数组 join() |
| C# | 不可变 | 线程安全 | StringBuilder |
更多内容,在后续的string部分深入。
三、dup #
源码 #
文件处理类程序都有相似的结构:一个处理输入的循环,在每个元素上执行计算处理,在处理的同时或最后产生输出。如文件的拷贝、打印、搜索、排序、统计等。
下面模拟Unix的uniq命令,其寻找相邻的重复行,并打印标准输入中多次出现的行,以重复次数开头。
| |
源码解读-fmt.print #
fmt 包的设计体现了 Go 语言的几个重要特性:
- 接口驱动:通过 Stringer、Formatter 等接口支持自定义格式化
- 性能优化:使用对象池、快速路径等减少分配
- 类型安全:通过反射和类型断言处理各种类型
- 错误处理:完善的 panic 恢复和错误报告
- 易用性:简洁的 API 设计,支持多种格式化选项 1. 核心接口定义
State 接口
| |
Formatter 接口
| |
Stringer 接口
| |
GoStringer 接口
| |
2. 核心数据结构
pp 结构体(打印状态)
| |
buffer 类型
| |
3. 主要函数族
动词*(verb)*:f:format、ln:line
| |
| |
%v的性能开销:
- 反射开销
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26func (p *pp) printArg(arg any, verb rune) { // 当 %v 遇到复杂类型时,会走到这里 default: if !p.handleMethods(verb) { // **使用反射 - 性能瓶颈** p.printValue(reflect.ValueOf(f), verb, 0) } } // 反射调用示例 func (p *pp) printValue(value reflect.Value, verb rune, depth int) { switch value.Kind() { case reflect.Struct: // **每个字段都需要反射访问** for i := 0; i < value.NumField(); i++ { field := value.Field(i) // 反射调用 p.printValue(field, verb, depth+1) } case reflect.Map: // **map 需要排序和反射访问** sorted := fmtsort.Sort(value) // 反射排序 for _, kv := range sorted { p.printValue(kv.Key, verb, depth+1) // 反射 p.printValue(kv.Value, verb, depth+1) // 反射 } } } - 接口方法调用开销: String() 方法调用
| |
- 内存分配问题
| |
Printf 系列(格式化打印)
| |
Print 系列(默认格式)
| |
Println 系列(带换行)
| |
4. 核心处理逻辑
doPrintf - 格式化字符串解析
| |
printArg - 参数打印
| |
5. 类型格式化方法
整数格式化
| |
字符串格式化
| |
6. 接口方法处理
handleMethods - 接口方法调用
| |
7. 性能优化
对象池复用
| |
8. 错误处理
panic 恢复
| |
| |
更多详情请参阅源码和godoc对fmt包的说明文档。